
Updated on January 4th, 2023: removed references to SQS, that is not actually used in the proposed implementation.
In that case, we need to invoke some asynchronous APIs, poll an endpoint to check when it has finished working, and then read the result, which is paginated, so we need multiple APIs call. Wouldn’t be super cool to just drop files in an S3 bucket, and after some minutes, having their content in another S3 bucket?
Let’s see how to use AWS Lambda and SNS to automatize all the process!
Overview of the process
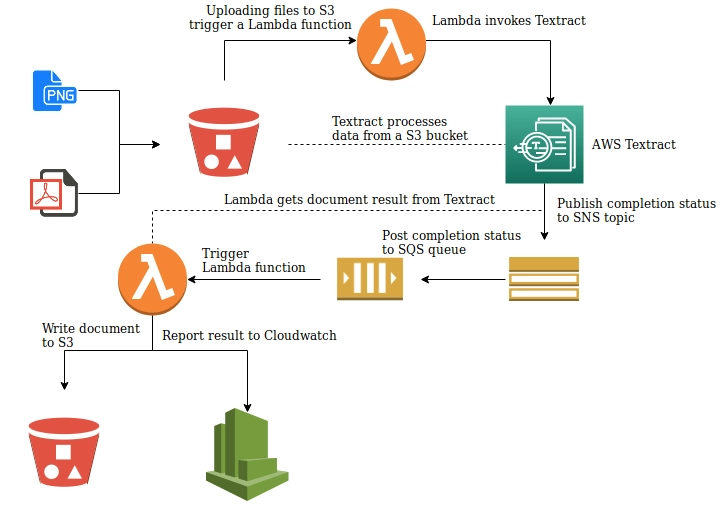
This is the process we are aiming to build:
Drop files to an S3 bucket;
A trigger will invoke an AWS Lambda function, which will inform AWS Textract of the presence of a new document to analyze;
AWS Textract will do its magic, and push the status of the job to an SNS topic;
The SNS topic will invoke another Lambda function, which will read the status of the job, and if the analysis was successful, it downloads the extracted text and save to another S3 bucket (but we could replace this with a write over DynamoDB or others database systems);
The Lambda function will also publish the state over Cloudwatch, so we can trigger alarms when a read was unsuccessful.
Since a picture is worth a thousand words, let me show a graph of this process.
While I am writing this, Textract is available only in 4 regions: US East (Northern Virginia), US East (Ohio), US West (Oregon), and EU (Ireland). I strongly suggest therefore to create all the resources in just one region, for the sake of simplicity. In this tutorial, I will use eu-west-1.
S3 buckets
First of all, we need to create two buckets: one for our raw file, and one for the JSON file with the extracted test. We could also use the same bucket, theoretically, but with two buckets we can have better access control.
Since I love boring solutions, for this tutorial I will call the two buckets textract_raw_files and textract_json_files. Official documentation explains how to create S3 buckets.
Invoke Textract
The first part of the architecture is informing Textract of every new file we upload to S3. We can leverage the S3 integration with Lambda: each time a new file is uploaded, our Lambda function is triggered, and it will invoke Textract.
The body of the function is quite straightforward:
1from urllib.parse import unquote_plus 2You can find a copy of this code hosted over Gitlab.
As you can see, we receive a list of freshly uploaded files, and for each one of them, we ask Textract to do its magic. We also ask it to notify us, when it has finished its work, sending a message over SNS. We need therefore to create an SNS topic. It is well explained how to do so in the official documentation.
When we have finished, we should have something like this:
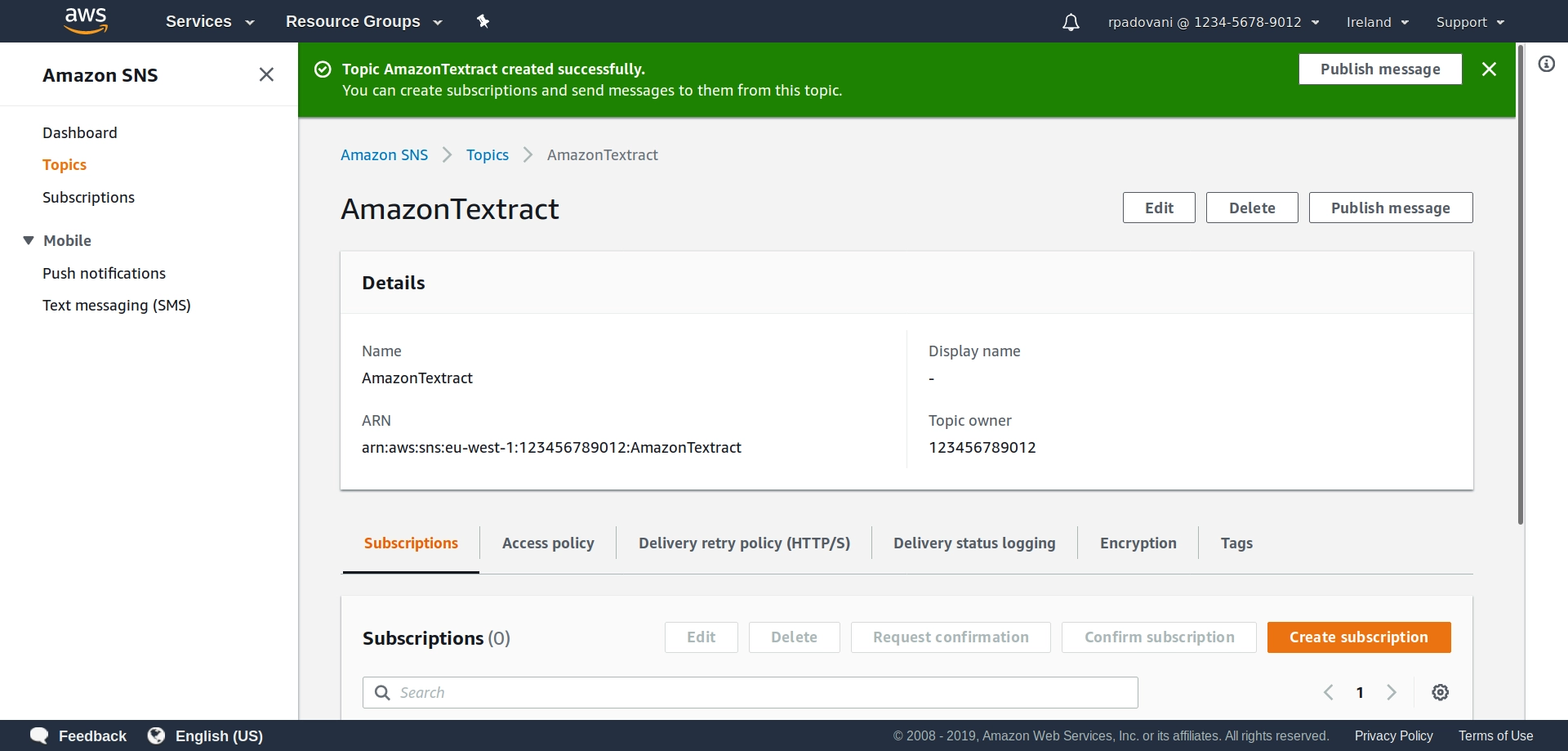
We copy the ARN of our freshly created topic and insert it in the script above in the variable SNS_TOPIC_ARN.
Now we need to actually create our Lambda function: once again the official documentation is our friend if we have never worked with AWS Lambda before.
Since the only requirement of the script is boto3, and it is included by default in Lambda, we don’t need to create a custom package.
At least, this is usually the case :-) Unfortunately, while I am writing this post, boto3 on Lambda is at version boto3-1.9.42, while support for Textract landed only in boto3-1.9.138. We can check which version is currently on Lambda from this page, under Python Runtimes: if boto3 has been updated to a version >= 1.9.138, we don’t have to do anything more than simply create the Lambda function. Otherwise, we have to include a newer version of boto3 in our Lambda function. But fear not! The official documentation explains how to create a deployment package. Update Oct ‘19: this is no longer the case, AWS has updated the boto3 package included in the Lambda runtime.
We need also to link an IAM role to our Lambda function, which requires some additional permission:
AmazonTextractFullAccess: this gives access also to SNS, other than Textract
AmazonS3ReadOnlyAccess: if we want to be a bit more conservative, we can give access to just the
textract_raw_filesbucket.
Of course, other than that, the function requires the standard permissions to be executed and to write on Cloudwatch: AWS manages that for us.
We are almost there, we need only to create the trigger: we can do that from the Lambda designer! From the designer we select S3 as the trigger, we set our textract_raw_files bucket, and we select All object create events as Event type.
If we implemented everything correctly, we can now upload a PDF file to the textract_raw_files, and over Cloudwatch we should be able to see the log of the Lambda function, which should say something similar to Document detection for textract_raw_files/my_first_file.pdf.
Now we only need to read the extracted text, all the hard work has been done by AWS :-)
Read data from Textract
AWS Textract is so kind to notify us when it has finished extracting data from PDFs we provided: we create a Lambda function to intercept such notification, invoke AWS Textract and save the result in S3.
The Lambda function needs also to support pagination in the results, so the code is a bit longer:
1import json 2import boto3 3You can find a copy of this code hosted over Gitlab.
Again, this code has to be published as a Lambda function. As before, it shouldn’t need any special configuration, but since it requires boto3 >= 1.9.138 we have to create a deployment package, as long as AWS doesn’t update the Lambda runtime.
After we have uploaded the Lambda function, from the control panel we set as trigger SNS, specifying as ARN the ARN of the SNS topic we created before - in our case, arn:aws:sns:eu-west-1:123456789012:AmazonTextract.
We need also to give the IAM role which executes the Lambda function new permissions, in addition to the ones it already has. In particular, we need:
AmazonTextractFullAccess
AmazonS3FullAccess: in production, we should give access to just the
textract_json_filesbucket.
This should be the final result:
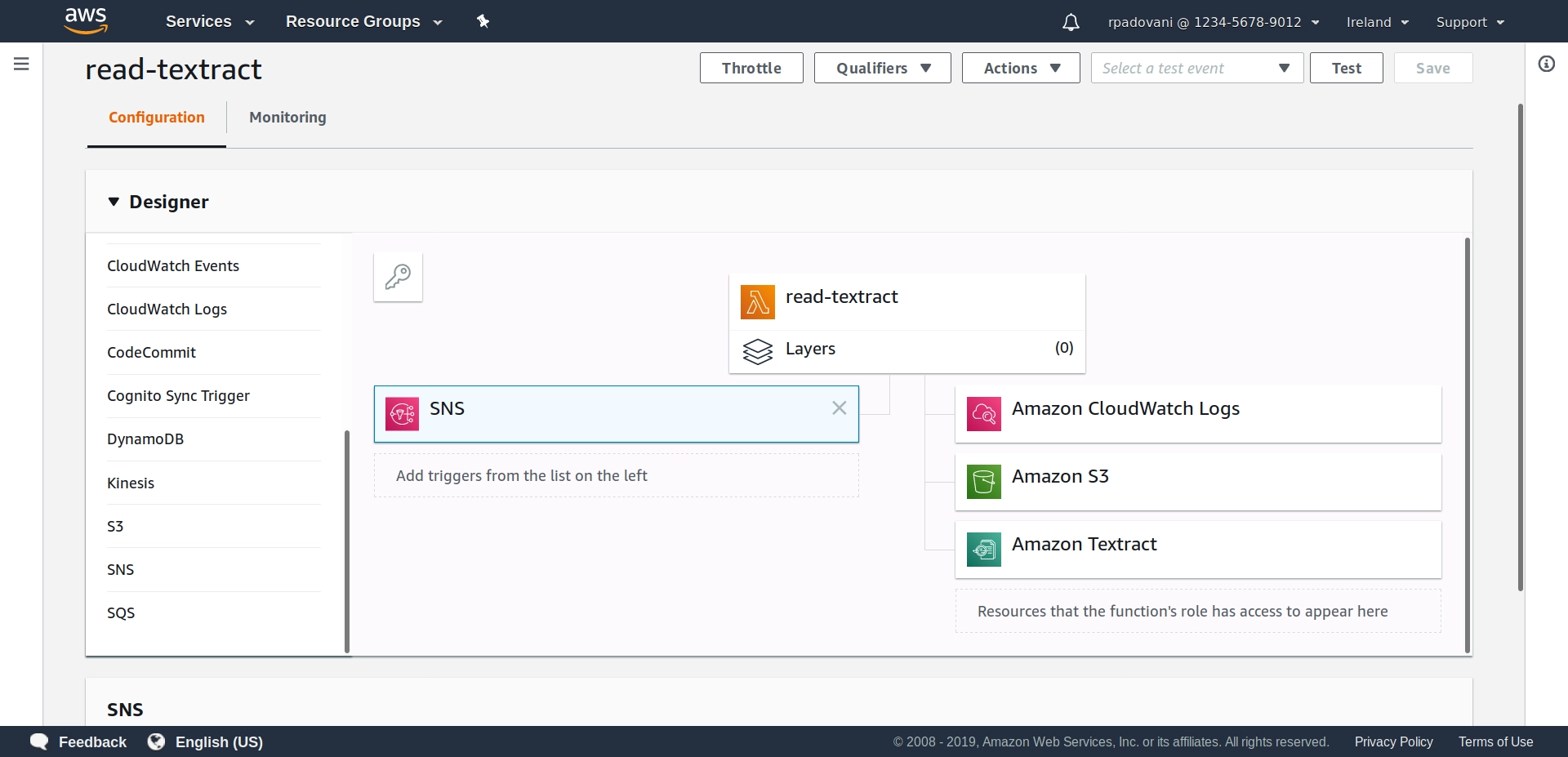
And that’s all! Now we can simply drop any document in a supported format to the textract_raw_files bucket, and after some minutes we will find its content in the textract_json_files bucket! And the quality of the extraction is quite good.
Known limitations
Other than being available in just 4 locations, at least for the moment, AWS Textract has other known hard limitations:
The maximum document image (JPEG/PNG) size is 5 MB.
The maximum PDF file size is 500 MB.
The maximum number of pages in a PDF file is 3000.
The maximum PDF media size for the height and width dimensions is 40 inches or 2880 points.
The minimum height for text to be detected is 15 pixels. At 150 DPI, this would be equivalent to 8-pt font.
Documents can be rotated a maximum of +/- 10% from the vertical axis. Text can be text aligned horizontally within the document.
Amazon Textract doesn’t support the detection of handwriting.
It has also some soft limitations that make it unsuitable for mass ingestion:
Transactions per second per account for all Start (asynchronous) operations: 0.25
Maximum number of asynchronous jobs per account that can simultaneously exist: 2
So, if you need it for anything but testing, you should open a ticket to ask for higher limits, and maybe poking your point of contact in AWS to speed up the process.
That’s all for today, I hope you found this article useful! For any comment, feedback, critic, leave a comment below, or drop an email at [email protected].
Regards,
R.
Comments